
Last updated: July 17, 2022
Do you have a PDF document from which you want to extract all the text? What about scanned images whose text you want to convert and edit? Here are some of the most common questions I've seen in my workplace when working with these files.
We have already seen a chrome extension that allows you to copy text from an image, today I will tell you in detail about various ways, with which you can extract text or image from a PDF file. Extraction results will vary depending on the type and quality of text or image in the PDF. This means that your results will vary depending on the tool you use, so it is best to try as many of the options listed below as possible to get the best results.
Extract text or image from a PDF
The easiest and quickest way to get started is to try an onlinePDF text extractor. These are usually free and can give you exactly what you're looking for without having to install anything on your computer. Here are the ones I used with very good results:
ExtractPDF
ExtractPDF is a free tool for recover images, text and fonts from a PDF file. Quick and easy to use, simply download your document or indicate the URL address of the PDF file you want to use and start the extraction. The only limitation is that the maximum PDF file size is 10 MB. This is a bit small; so if you have a larger file, try to compress PDF or to test the other methods cited in the article. Completely free, ExtractPDF can be used without any prior registration.

Overall, the ExtractPDF online tool works very well, but I encountered some problems with a PDF file that gave me a strange result. The text is extracted just fine, but for some reason there is a line break after each word! Not a big problem for a small PDF file, but definitely a problem for files with a lot of text. If this happens to you, try the following tool.
Online OCR
Online OCR usually tends to work for documents that couldn't be converted properly with ExtractPDF, so it's a good idea to try both services to see which one will give you the best output in terms of quality. Online OCR also has some nicer features that can be very handy for anyone with a large PDF file who only needs to convert some text on a few pages, and not the entire document.
The first thing you should do is go ahead and create a free account. It's a bit annoying, but if you don't sign up for a free account, it will partially convert your PDF rather than the entire document. This means that instead of only being able to download a 5 MB document, you will be able to download up to 100 MB per file with an always free account.
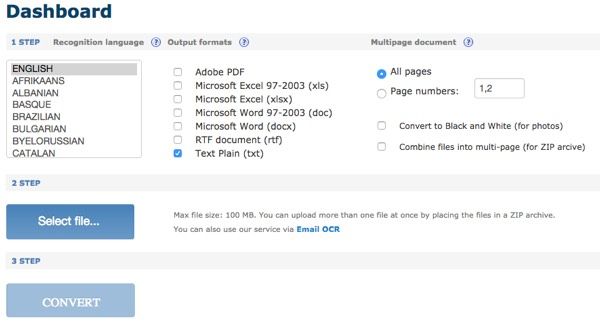
To use Online OCR, go to the following address: www.onlineocr.net, choose a language, then choose the type of output formats you want for the converted file. You have two options and you can choose more than one if you want. Under Multipage Document, you can select page numbers, and then choose only the pages you want to convert. Then you select the file. Finally, click Convert!
Online OCR did a great job converting my PDF files because it was able to maintain the actual layout of the text during the test I performed. I had taken a Word document taking into account various hyphens, different font sizes, etc. And the software still managed to convert everything into a PDF file. Then I used Online OCR to convert back to Word format and the result was about 95% the same as the original. That's pretty impressive to me.
Free Online OCR
Speaking of image and text as well as OCR, let me mention another great site that works really well for images. Free Online OCR was very good and very accurate when extracting text from my test images. I then took some photos from my iPhone of various book pages, brochures, etc., and was surprised how well the tool was able to convert the text.

To use it, start by choosing your file then click on the Download button. On the next screen, there is a group of options and an image preview. You can crop the part you want to extract. Then click the OCR button and your converted text appears below the image preview. It also has no limits, which is really nice.
In addition to online services, there are two freeware PDF converters, which I definitely want to mention in case you need software that runs locally on your computer to do these types of conversions. With online services, you will always need the Internet, something that is not always possible for everyone at all times. However, I noticed that the quality of conversions from freeware programs was noticeably lower than those from websites.
A-PDF Text Extractor
A-PDF Text Extractor is a freeware that does indeed do a pretty impressive job of extracting text from PDF files. Once you download and install it, click the Open button to choose your PDF file. Then click Extract text to start the process.

You will be required to choose a location to store the output file and the extraction will finally begin. You can also click the Option button, which will allow you to choose only certain pages to extract and the extraction type. The second option is interesting because it extracts the text in different layouts and it is indeed very interesting to try all three to see which ones give you the best result and expected output.
PDF2Text driver
PDF2Text driver does a decent job of extracting text. He unfortunately has no options; just you add files or folders, you convert and hope for the best. It worked well on some PDF files, but for the majority of them there were several issues.

Click Add Files, and then click Convert. When the conversion is complete, click Browse to open the file. Your performance will vary using this program, so don't expect too much.
Also, it's worth noting that if you're in a corporate environment or you can get your hands on a copy of Adobe Acrobat at work, then you can really get much better results.
Acrobat is obviously not free, but the software does have options for converting your projects from PDF to Word, Excel and HTML format. It also did the best rendering in maintaining the original document structure and complicated text conversion.