Les meilleurs outils OSINT gratuits pour 2025 incluent urlscan.io pour l'analyse d'URL, Maltego CE pour la visualisation de données et Shodan pour explorer les objets connectés. D'autres solutions comme Google Dorks permettent de trouver des fichiers sensibles, tandis que Have I Been Pwned et SpiderFoot HX facilitent la vérification des fuites de données et la collecte automatisée de renseignements publics.
L'OSINT, ou renseignement en sources ouvertes, c'est un domaine passionnant où tu peux exploiter des infos accessibles à tous pour découvrir des pépites.
Ce qui rend l'OSINT vraiment génial, ce sont les outils ! Qui n'aime pas dénicher un site web qui te déniche des infos en un clic ou une extension qui rend ton travail encore plus fluide ?
Dans cette liste, j'ai rassemblé dix outils gratuits que tu peux utiliser dès maintenant. Que tu sois étudiant, passionné, ou même un pro, ces outils sont faits pour toi.
1. urlscan.io
Je commence par un outil que j'adore : urlscan.io. C'est un site qui te permet d'analyser une URL en profondeur. Tu obtiens des infos détaillées sur tout ce que la page charge, les connexions réseau qu'elle fait, et bien plus encore.
C’est super pratique si tu veux vérifier la sécurité d'un site ou analyser des menaces potentielles.
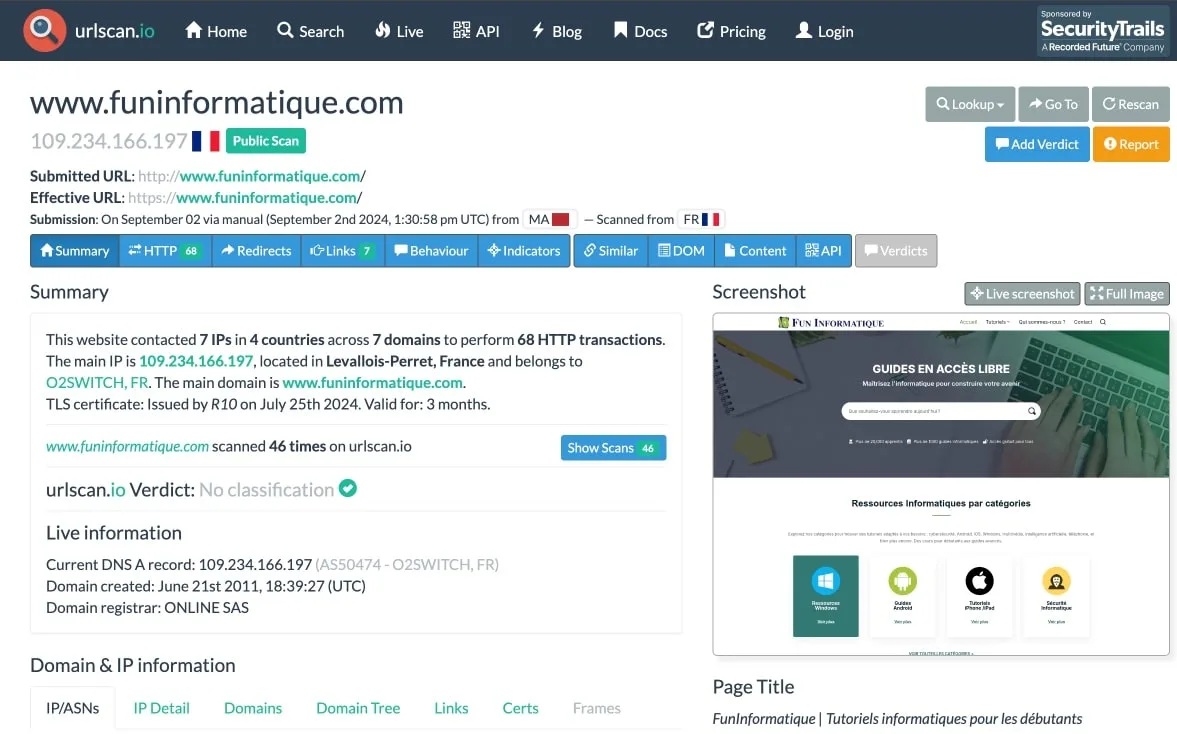
Ce qui est cool avec urlscan.io, c’est sa simplicité. Tu colles l’URL, tu cliques, et en quelques secondes, tu as un rapport complet sous les yeux.
Tu peux voir les serveurs contactés, les scripts exécutés, et même une capture d'écran de la page.
2. Internet Archive
Tu connais l'Internet Archive, ou la Wayback Machine ? C'est une sorte de bibliothèque numérique qui stocke des versions anciennes de sites web.
En effet, tu peux voir à quoi ressemblait un site à une époque donnée, ce qui est super utile pour retrouver des infos qui ont été supprimées ou modifiées.
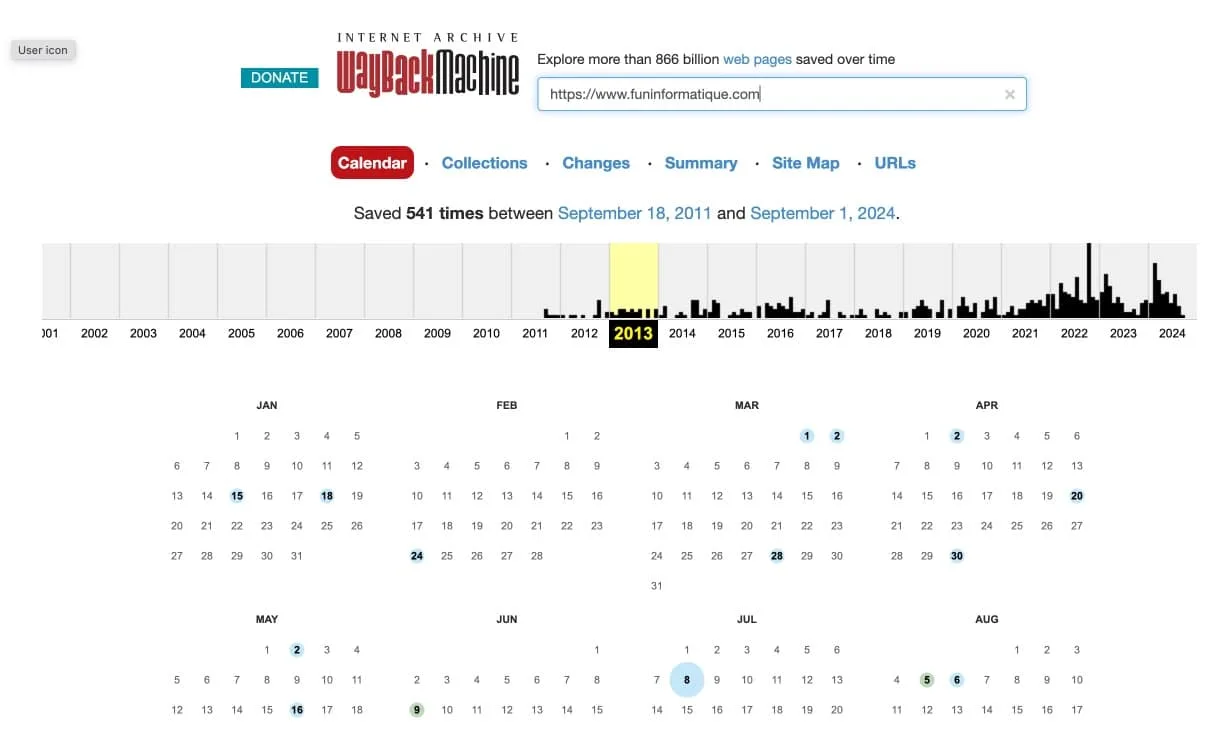
Avec cet outil, tu choisis une date et hop, tu navigues dans le passé du web. C’est génial pour voir comment un site a évolué ou pour retrouver des infos disparues.
3. Search by Image
Si tu bosses avec des images, le plugin Search by Image pour Chrome et Firefox va te plaire. Il te permet de faire une recherche inversée d'une image directement depuis ton navigateur. En un clic, tu lances une recherche sur plusieurs moteurs pour voir où elle a été utilisée ailleurs sur le web.
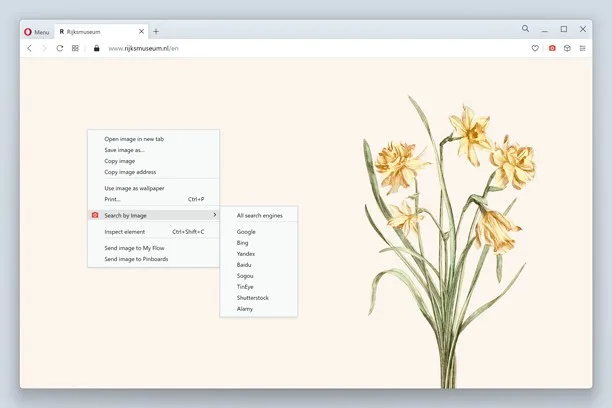
Le plus pratique, c'est que ça t'ouvre automatiquement plusieurs onglets avec les résultats de chaque moteur.
Que tu cherches l'origine d'une image, son contexte, ou d'autres utilisations en ligne, Search by Image te fait gagner un temps fou.
4. Maltego CE
Si tu es un lecteur fidèle de FunInformatique, tu connais sûrement déjà Maltego, car j'en ai parlé dans plusieurs articles. Pour ceux qui ne connaissent pas encore, Maltego Community Edition est un outil très puissant pour analyser et visualiser des informations.
C’est particulièrement utile pour l’OSINT, c’est-à-dire la recherche d’informations disponibles publiquement.
Maltego te permet de voir les connexions entre différentes données, comme des personnes, des entreprises, des sites web, et bien plus encore. Mais ce n’est pas tout.
En plus de relier ces informations, Maltego peut aussi t’aider à découvrir d'identifier des numéros de téléphone, des adresses email, des profils sur les réseaux sociaux, et même des informations sur les domaines web.
Le fonctionnement de Maltego repose sur l’utilisation de "transforms", qui sont des petites requêtes qui vont chercher des données sur internet.
Par exemple, si tu cherches un nom de domaine, Maltego peut te montrer à qui il appartient, les emails associés, les sous-domaines, et d’autres informations techniques.
Pour télécharger Maltego, cliquez ici : https://www.maltego.com/downloads/
5. Shodan
Ensuite, parlons de Shodan. Cet outil est un moteur de recherche spécialisé dans les objets connectés. Contrairement à Google, qui cherche des pages web, Shodan explore les appareils qui sont connectés à Internet.
Tu peux y trouver des caméras de sécurité, des serveurs, des imprimantes, et même des systèmes de contrôle industriel comme les SCADA.
Certains l'appellent le moteur de recherche pour les hackers, mais il est aussi extrêmement utile pour quiconque s'intéresse à la sécurité en ligne.
En OSINT, Shodan te permet de découvrir l’infrastructure d’une entreprise. De plus, il t’aide à repérer des vulnérabilités potentielles.
Par exemple, tu peux l'utiliser pour identifier les caméras de surveillance d'un bâtiment. En parallèle, tu peux explorer les dispositifs connectés dans une zone géographique donnée.
6. Google Dorks
Google Dorks, c'est une technique pour utiliser Google comme un pro. En combinant des opérateurs de recherche spécifiques, tu peux dénicher des infos cachées ou mal protégées sur des sites web.
En effet, tu peux par exemple trouver des fichiers sensibles, des bases de données exposées, ou des pages non indexées avec une simple recherche bien formulée.
C'est un classique de l'OSINT, et même si c'est une technique qui existe depuis longtemps, elle reste ultra puissante.
7. SpiderFoot HX
SpiderFoot HX est un super outil qui rend la recherche d’infos en ligne beaucoup plus facile. Il se charge de recueillir des données à partir de centaines de sources sur Internet.
Avec SpiderFoot HX, tu peux rapidement obtenir un aperçu détaillé de ce qu’on peut trouver sur une entreprise, une personne ou un site web spécifique.
Par exemple, il peut te montrer des informations sur les adresses IP, les domaines, les profils sur les réseaux sociaux, et plus encore. C’est comme avoir un assistant qui te donne toutes les infos importantes en un rien de temps !
La version gratuite est parfaite pour te lancer et explorer les fonctionnalités de base. Tu pourras découvrir comment l’outil fonctionne et voir ce qu’il peut faire sans débourser un centime.
Pour télécharger SpiderFoot, cliquez sur le lien suivant : https://github.com/smicallef/spiderfoot
8. Have I Been Pwned
Have I Been Pwned est un outil très pratique pour vérifier si tes adresses e-mail ou tes informations personnelles ont été compromises dans des fuites de données.
En quelques étapes simples, tu peux entrer ton adresse e-mail, et l'outil te dira immédiatement si elle figure dans des bases de données de fuites.
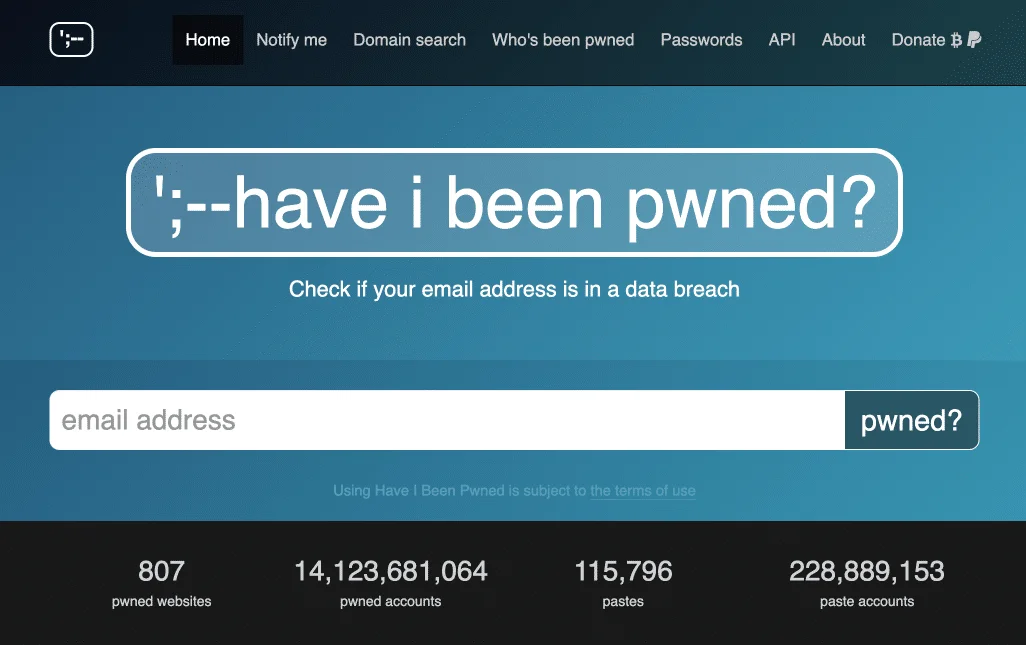
C’est un excellent moyen de rester informé et de protéger tes données personnelles contre les compromissions.
9. CertGraph
CertGraph est une autre plateforme puissante qui te permet d'explorer les dispositifs connectés et les certificats SSL/TLS sur Internet.
Grâce à cet outil, tu peux identifier les vulnérabilités potentielles et comprendre comment les services sont configurés à l’échelle mondiale.
De plus, il te permet de voir les configurations de sécurité des services en ligne, ce qui est crucial pour évaluer les risques. De plus, l’accès à CertGraph est gratuit pour des recherches de base.
10. The Harvester
Enfin, The Harvester est un excellent outil pour la collecte d’informations sur les adresses email et les noms de domaine.
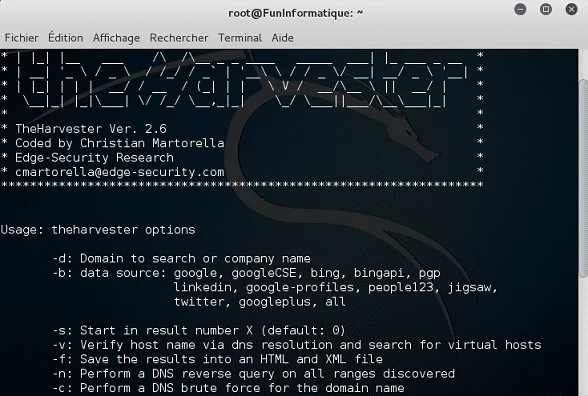
Il est utilisé principalement pour la reconnaissance initiale dans les tests de pénétration et les enquêtes de cybersécurité, en recueillant des informations à partir de moteurs de recherche et de sources publiques.
Vos articles sont-ils encore à jour en 2026 ?
Notre IA analyse chaque article de votre site et vous dit exactement quoi corriger pour rester visible en 2026.
Lancer mon audit gratuit
Votre avis nous intéresse